Understanding the Difference Between ID Token, Access Token, and Refresh Token in OAuth & OpenID Connect
OAuth 2.0 and OpenID Connect are widely used frameworks for authorization and authentication. These protocols use tokens to securely exchange and validate information between systems. However, understanding the purpose and difference between ID Token, Access Token, and Refresh Token can be challenging. In this article, we’ll break down each token and their specific roles in OAuth and OpenID Connect.
What Is an ID Token?
The ID Token is a JSON Web Token (JWT) issued by the identity provider (IdP) as part of the OpenID Connect protocol. Its primary purpose is to authenticate the user and confirm their identity to the client application. The ID Token contains information about the user, such as:
- Subject (sub): A unique identifier for the user.
- Issuer (iss): The identity provider that issued the token.
- Expiration (exp): The token's validity period.
- Claims: Additional information like the user’s email, name, or roles.
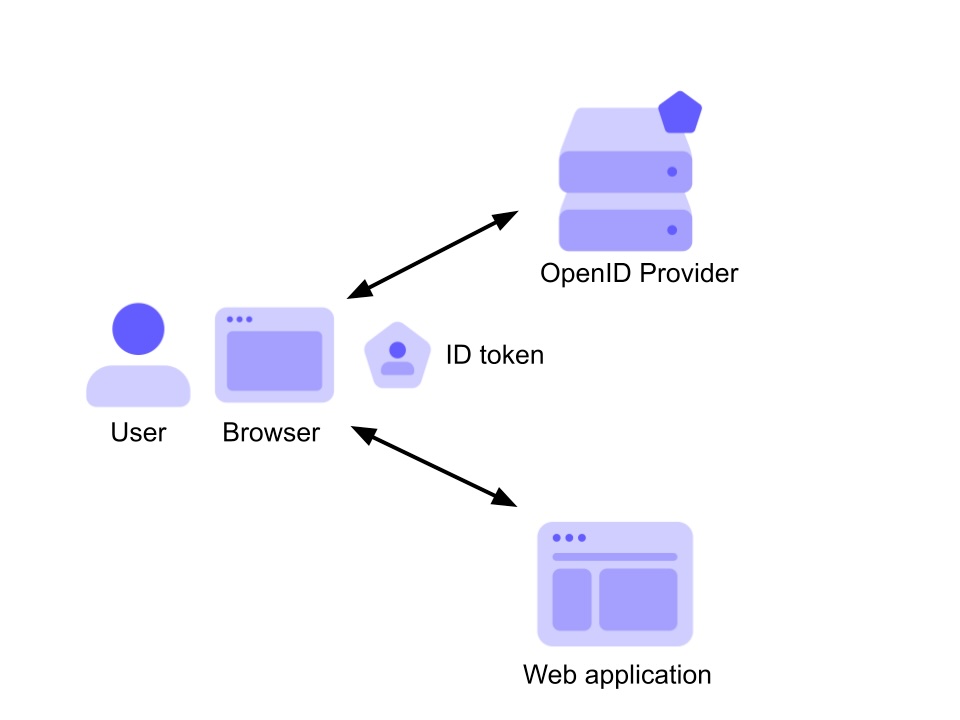
Illustration of an ID Token in action
What Is an Access Token?
The Access Token is a token issued by the authorization server, enabling the client application to access protected resources (such as APIs) on behalf of the user. Unlike the ID Token, the Access Token:
- Does not contain user identity information.
- Is designed to be presented to APIs or resource servers as proof of authorization.
- Has a short lifespan for security purposes.
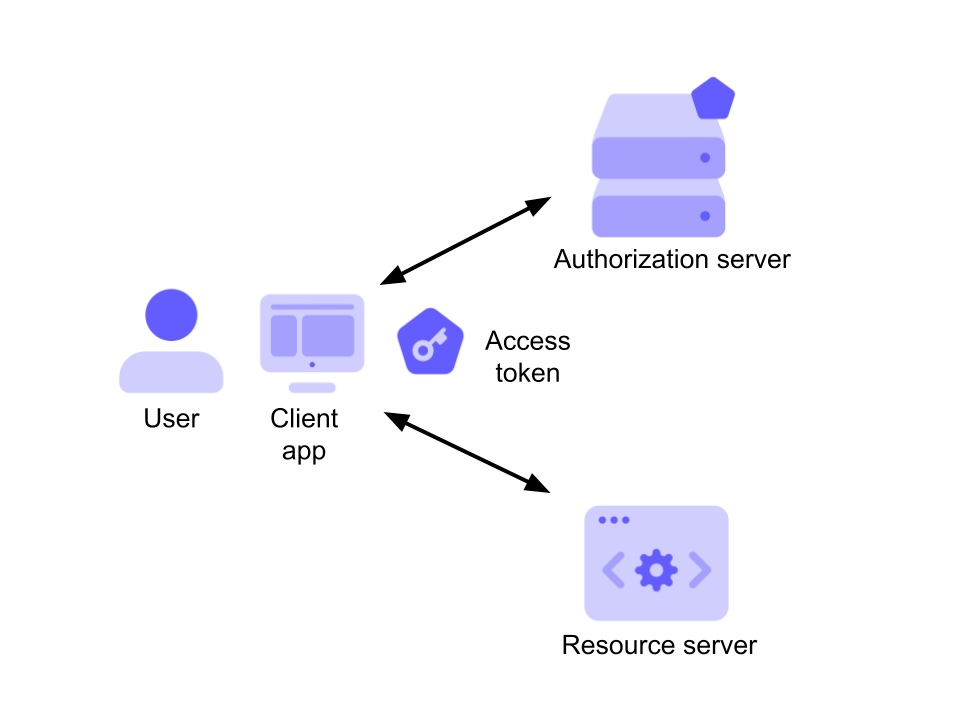
Illustration of an Access Token in action
What Is a Refresh Token?
The Refresh Token is a long-lived token used to obtain a new Access Token without requiring the user to log in again. It is issued alongside the Access Token during the authorization process and is stored securely by the client application. Refresh Tokens:
- Are typically not sent to APIs or resource servers.
- Have a longer validity period than Access Tokens.
- Are subject to strict security practices to prevent misuse.
Key Differences at a Glance
| Token Type | Purpose | Contains User Info? | Intended Audience |
|---|---|---|---|
| ID Token | User authentication and identity confirmation. | Yes | Client application |
| Access Token | Authorize access to protected resources. | No | APIs or resource servers |
| Refresh Token | Obtain new Access Tokens without re-authentication. | No | Authorization server |

Summary: ID Token vs Access Token vs Refresh Token
Conclusion
Understanding the distinct roles of ID Tokens, Access Tokens, and Refresh Tokens is essential for designing secure and efficient authentication and authorization workflows. While the ID Token is central to user authentication, the Access Token ensures authorized API access, and the Refresh Token enhances user experience by reducing the need for frequent logins.
By using these tokens effectively, you can create robust and secure systems that adhere to modern authentication and authorization standards.